[Server] 정적 페이지 vs 동적 페이지
by 캐떠린원래 Java는 웹 개발을 할 수 있는 언어가 아니다. 근데 우리는 어떻게 자바로 웹 개발을 할 수 있을까?
바로 '웹 구현' 이라는 확장팩을 설치했기 때문에 자바로 웹 개발이 가능한 것이다!
서블릿(Servlet)은 자바(JDK, JRE) 베이스에 웹 구현 기능(.jar)이 추가된 것이다.
❓ 나도 모르는 새에 웹 구현 기능.jar은 언제 설치가 되었을까?
⇒ 아파치 톰캣이 가져왔다!!
💡 아파치 톰캣의 역할
- 웹 서버의 역할
- 자바로 서블릿 or JSP를 구현할 수 있는 수많은
*.jar파일 제공- 서버 측에서 서블릿과 JSP를 동작하게 만드는 역할
💡 아파치 vs 톰캣
: 사실 아파치와 톰캣은 서로 다른 프로그램이다.
- 아파치: 웹 서버 → 정적인 페이지 → 페이지를 요청받으면 찾아서 돌려주는 역할 ⇒ 굉장히 단순한 역할
- 톰캣: 응용 프로그램 서버(Web Application Server, WAS), 서블릿 컨테이너 → 동적인 페이지
정적 페이지 vs 동적 페이지
💡
.html: 정적인 페이지
.do: 동적인 페이지
⇒ 클라이언트는 특정 페이지를 봤을 때, 해당 페이지가 정적 vs 동적인 페이지 중 무엇으로 만들어졌는지 구분하지 못한다.
But 2개의 상이한 페이지가 우리에게 도달해서 올 때까지의 과정은 상이하다.
이제부터 페이지가 우리에게 도달해서 오는 과정을 알아보자!
정적인 페이지
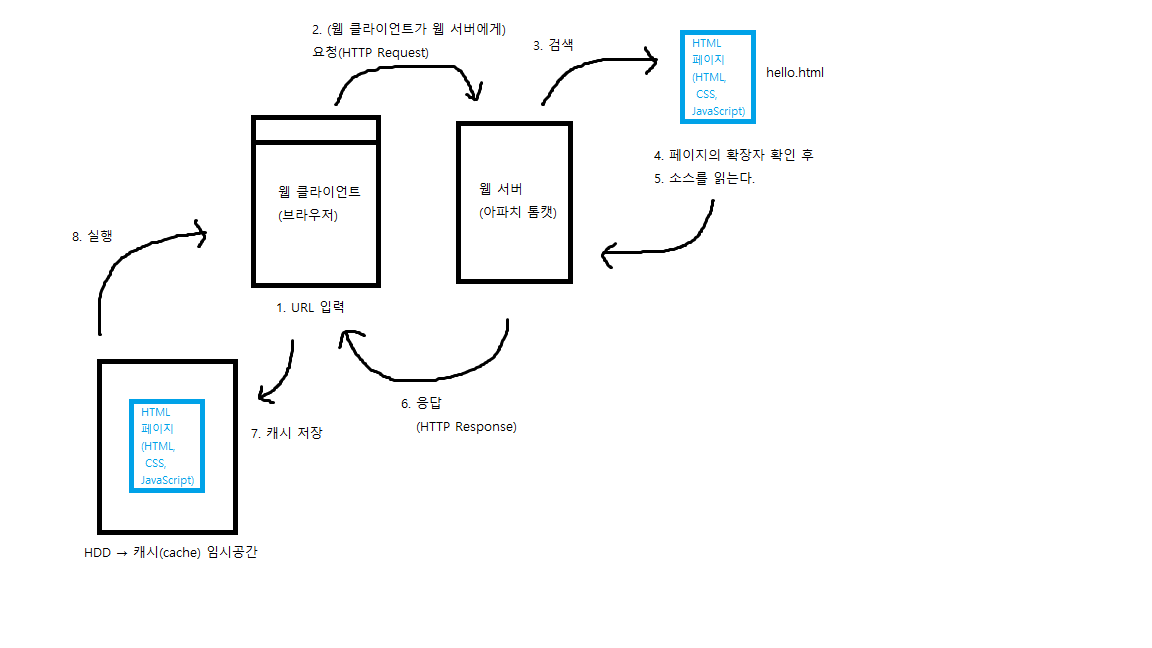
1. 우리가 웹 클라이언트(브라우저)에 URL을 입력하면
2. 웹 클라이언트(브라우저)가 웹 서버(아파치)에게 요청을 한다. → HTTP Request
3. 웹서버는 해당 페이지를 검색을 해서 찾고
4. 페이지의 확장자를 확인한 후,
5. 소스를 읽는다.
6. 읽은 소스를 별도 처리 없이 웹 클라이언트(브라우저)에게 응답(전달)하고 → HTTP Response
7. 웹 클라이언트(브라우저)는 우리의 컴퓨터 하드디스크에 해당 페이지의 캐시를 저장한다.
8. 하드디스크에 저장한 캐시를 불러와 페이지를 실행하여 사용자(우리)는 페이지를 볼 수 있다.
동적인 페이지
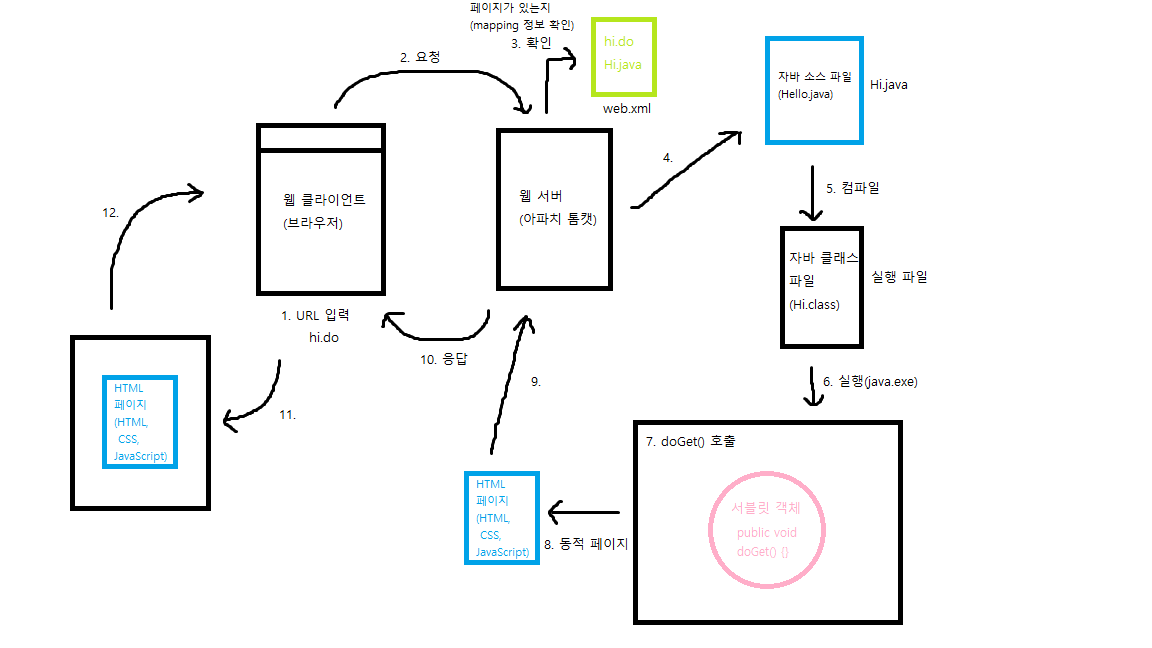
1. 우리가 웹 클라이언트(브라우저)에 URL을 입력하면
2. 웹 클라이언트(브라우저)가 웹 서버(아파치)에게 요청을 한다. → HTTP Request
3. 웹서버는 해당 페이지가 있는지 mapping 정보를 확인한 후
4. 자바 소스 파일을 찾아서
5. 컴파일을 진행한다.
6. 컴파일 후 해당 자바 클래스 파일을 실행하여
7. doGet 메서드를 호출한다.
8. doGet메서드가 반환한 동적 페이지를(서블릿이 만든 결과물에는 java 코드가 들어가지 않는다. 결과물에는 HTML 페이지만 존재한다. → java는 서버 측에서 이미 실행했고, HTML은 브라우저가 받아서 실행할 것이기 때문)
9. 웹 서버(톰캣)에 전달한 후,
10. 웹 서버는 웹 클라이언트(브라우저)에게 응답한다. → HTTP Response
11. 웹 클라이언트(브라우저)는 우리의 컴퓨터 하드디스크에 해당 페이지의 캐시를 저장한다.
12. 하드디스크에 저장한 캐시를 불러와 페이지를 실행하여 사용자(우리)는 페이지를 볼 수 있다.
동적인 페이지를 위의 과정을 통해 한 번 실행 후, 재 실행한다면 4~6번 과정은 재 실행되지 않는다.(Why? 실행 파일을 어디엔가 살려두었기 때문이다.) 따라서 3번 과정 후에 7번 doGet 메서드 호출이 진행된다.
❓ 왜 서버 측에서는 별도 처리 없이 소스 그대로 돌려줄까?
: HTML, CSS, JavaScript 언어는 실행하는 주체가 브라우저이다. 일을 처리하는 주체인 브라우저가 클라이언트이기 때문에 별도 처리 없이 소스 그대로 돌려준다!(웹 서버의 입장에서는 저 코드들이 이해할 수 없는 코드라고 인식을 하기 때문!)
❓ 왜 하드디스크에 저장을 해서 실행할까?
: 과거에는 회선이 굉장히 느렸었다. 방금 껐던 창을 다시 불러오는 등의 행위로 페이지가 재 실행 될 때마다 불러오는데 많은 시간이 소요되었다. → 비효율적
따라서 브라우저는 한 번이라도 열람한 자원들을 나의 하드디스크 캐시에 저장을 한 후, 페이지 재 방문 시 이를 재활용한다. 페이지를 방문하면 하드디스크의 캐시를 먼저 돌면서 캐시를 불러오고, 만일 캐시가 없다면 새로 불러오는 방법을 채택하게 된 것이다.
✓ 캐싱의 장점: 실행 속도가 빠르다, 트래픽이 발생되지 않아서 회선 비용도 절감할 수 있다.
❓ 그렇다면 회선이 빨라진 지금은 왜 아직 이 방법을 사용할까?
: 회선이 빨라진 만큼 주고받는 데이터의 크기도 커졌기 때문에 아직 이 구조가 물리적으로 유효하기 때문이다.
'Server' 카테고리의 다른 글
| [Server] JSP에 대하여 (2) | 2023.10.30 |
|---|---|
| [Server] 데이터 입력 및 데이터 수신 과정 톺아보기 (0) | 2023.10.29 |
| [Server] Servlet 관련 각종 Error Case (0) | 2023.10.22 |
| [Server] Servlet(서블릿) (0) | 2023.10.22 |
| [Server] 개발 환경 Setting :: Apache Tomcat, Eclipse (0) | 2023.10.22 |
블로그의 정보
All of My Records
캐떠린