[Oracle] 함수 :: 문자열 함수(String Function)
by 캐떠린문자열 함수, String Function
1. 대소문자 변환 함수
- upper(컬럼) : 대문자 변환
- lower(컬럼) : 소문자 변환
- initcap(컬럼) : 첫 문자를 대문자로, 나머지 문자는 소문자로 변경
- 영어에서만 유효
- varchar2 자료형에 해당
- 사용 예시
-- EX 1)
SELECT
first_name,
upper(first_name),
lower(first_name)
FROM employees;
-- EX 2)
SELECT
'abc',
INITCAP('abc'),
INITCAP('aBC')
FROM dual;
-- EX 3) 이름에 'AN' 포함된 직원 > 대소문자 구분 없이
--BEST
SELECT
first_name
FROM employees
WHERE lower(first_name) LIKE '%an%';
--Bad
SELECT
first_name
FROM employees
WHERE first_name LIKE '%an%' OR first_name LIKE '%AN%' OR first_name LIKE '%An%' OR first_name LIKE '%aN%';

2. 문자열 추출 함수
- substr() : Java의 substring()과 유사한 기능
- substr(컬럼, 시작 위치)
- substr(컬럼, 시작 위치, 가져올 문자 개수)
- 사용 예시
-- EX 1)
SELECT
address,
substr(address, 3, 5),
substr(address, 3)
FROM tblAddressbook;
-- EX 2)
SELECT
name,
ssn,
substr(ssn,1,2) AS 생년,
substr(ssn,3,2) AS 생월,
substr(ssn,5,2) AS 생일,
substr(ssn,8,1) AS 성별
FROM tblinsa;
-- EX 3)

3. 문자열 길이 함수
- length(컬럼)
- 사용 예시
-- 컬럼리스트에서 사용
SELECT name, length(name) FROM tblcountry;
-- 조건절에서 사용
SELECT name, length(name) FROM tblcountry WHERE LENGTH(name) > 3;
--ORA-00904: "LENG": invalid identifier > 실행 순서 때문
SELECT name, length(name) AS leng FROM tblcountry WHERE leng > 3;
--이건 가능 > 실행 순서
SELECT name, length(name) AS leng FROM tblcountry ORDER BY leng ASC;
-- 정렬에서 사용
SELECT name, length(name) FROM tblcountry ORDER BY length(name) DESC;
4. 문자열 검색 함수
- instr() : 검색어의 위치 반환 → Java의 indexOf 역할
- instr(컬럼, 검색어)
- instr(컬럼, 검색어, 시작 위치)
- instr(컬럼, 검색어, 시작 위치, -1) → lastIndexOf 역할(뒤에서 첫번째 위치부터 검색 시작) ※ 반환하는 위치는 앞에서부터의 위치를 반환
- 못 찾으면 0을 반환
- 사용 예시
SELECT
'안녕하세요. 홍길동님.',
instr('안녕하세요. 홍길동님.', '홍길동') AS r1,
instr('안녕하세요. 홍길동님.', '아무개') AS r2, --없는 사람 검색 시 0 반환
instr('안녕하세요. 홍길동님. 홍길동님', '홍길동') AS r3, --다수의 결과가 있는 경우, 첫번째 결과값 위치 반환
instr('안녕하세요. 홍길동님. 홍길동님', '홍길동', 11) AS r4,
instr('안녕하세요. 홍길동님. 홍길동님', '홍길동', instr('안녕하세요. 홍길동님. 홍길동님', '홍길동') + LENGTH('홍길동')) AS r5, --너무 복잡하여 다른 언어의 도움을 받음
instr('안녕하세요. 홍길동님. 홍길동님', '홍길동', -1) AS r6 --뒤에서 첫번째부터 검색을 하지만 반환하는 검색어의 위치는 앞에서부터 시작한 위치 반환
FROM dual;
5. 패딩
- 왼쪽 또는 오른쪽에 특정 문자를 채워서 문자열 길이를 맞추는 역할
- LPAD(), RPAD()
- Left Padding, Right Padding
- LPAD(컬럼, 개수, 문자) → '개수'만큼 '컬럼' 왼쪽에 '문자'를 채운다.
- RPAD(컬럼, 개수, 문자) → '개수'만큼 '컬럼' 오른쪽에 '문자'를 채운다.
- LPAD(컬럼, 개수), RPAD(컬럼, 개수)만 입력 시 빈칸을 '공백'으로 채운다.
- 사용 예시
SELECT
lpad('a', 5), -- java의 '%5s'와 동일
lpad(123,5,0),
lpad('a', 5, 'b'),
lpad('aa', 5, 'b'),
lpad('aaa', 5, 'b'),
lpad('aaaa', 5, 'b'),
lpad('aaaaa', 5, 'b'), -- 여기서 'b'는 의미 없음. > 이미 'aaaaa'로 5자리를 채웠기 때문
lpad('1', 3, '0'),
rpad('1', 3, '0')
FROM dual;
6. 공백 제거
- trim(컬럼) : 양쪽 공백 제거
- ltrim(컬럼) : 왼쪽 공백 제거
- rtrim(컬럼) : 오른쪽 공백 제거
- 사용 예시
SELECT
' 하나 둘 셋 ',
trim(' 하나 둘 셋 '),
ltrim(' 하나 둘 셋 '),
rtrim(' 하나 둘 셋 ')
FROM dual;
7. 문자열 치환
1) replace(컬럼, 찾을 문자열, 바꿀 문자열)
SELECT
REPLACE('홍길동', '홍', '김'),
REPLACE('홍길동', '이', '김'), -- 영향 X > 찾을 문자열인 '이'가 없기 때문
REPLACE('홍길홍', '홍', '김')
FROM dual;
2) regexp_replace() → 정규식 사용 가능
SELECT
name,
regexp_replace(name, '김.{2}', '김OO'),
tel,
regexp_replace(tel, '(\d{3})-(\d{4})-\d{4}', '\1-\2-XXXX')
FROM tblinsa;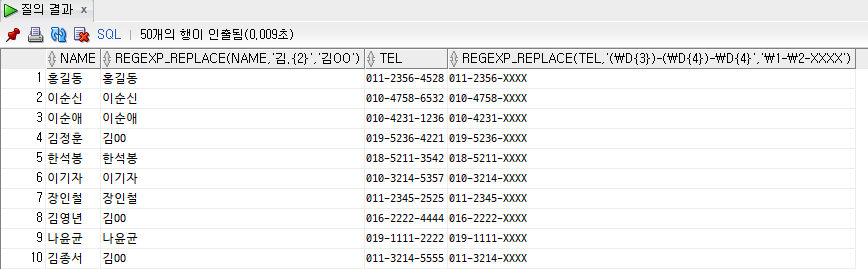
3) decode(컬럼, 찾을 문자열, 바꿀 문자열, [찾을 문자열, 바꿀 문자열] X N)
SELECT
gender,
CASE
WHEN gender = 'm' THEN '남자'
WHEN gender = 'f' THEN '여자'
END AS g1,
replace(replace(gender, 'm', '남자'), 'f', '여자') AS g2, -- 가독성 떨어짐. **해당하는 값이 없으면 원본을 반환
decode(gender, 'm', '남자', 'f', '여자') AS g3 -- 다중 치환 시 유용. **해당하는 값이 없으면 null값 반환
FROM tblcomedian;
-- decode가 CASE-END와 성질이 비슷 > 해당하지 않는 값은 null값을 반환한다. > decode가 코드를 줄여줄 수 있음.
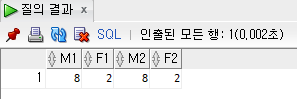
--tblComedian. 남자수? 여자수?
SELECT
count(CASE
WHEN gender = 'm' THEN 1
END) AS m1,
count(CASE
WHEN gender = 'f' THEN 1
END) AS f1,
count(decode(gender, 'm', 1)) AS m2,
count(decode(gender, 'f', 1)) AS f2
FROM tblcomedian;
*글 작성에 참고한 내용: 학원 쌤의 열정적인 수업
* 글 작성에 참고한 포스트: https://gent.tistory.com/22 이 분 정리 짱짱!
'DB > Oracle' 카테고리의 다른 글
| [Oracle] 함수 :: 날짜 시간 함수(date time function) (0) | 2024.03.18 |
|---|---|
| [Oracle] 함수 :: 형변환 함수(casting function) (0) | 2024.03.18 |
| [Oracle] 함수 :: 숫자 함수, 수학 함수(Numerical Function) (3) | 2024.03.16 |
| [Oracle] 함수 :: 집계 함수(Aggregation Function) (2) | 2024.03.16 |
| [Oracle] 컬럼 리스트에서 할 수 있는 행동 :: SELECT절 (2) | 2024.03.15 |
블로그의 정보
All of My Records
캐떠린